Date: 25 Jan 2022
Table of Contents
In our Graphite storage daemon Go-Carbon, we are using Trie and DFA for supporting globbing queries. I had an old post explaining about how it works and performs: To glob 10M metrics: Trie * DFA = Tree² for Go-Carbon (the graphite storage node daemon).
In this post, I will explain how to make the trie * DFA algorithm supports concurrent and realtime index.
Before acquiring the concurrent capability, the Go-Carbon daemon indexes new metrics by scanning the file system and building a new trie tree every 5 minutes and a full file system scan might take 10+ minutes and in some extreme cases, half an hour or more. This could be annoying for some cases. What’s more, this also implies higher memory usage as Go-Carbon needs to maintain 2 copies of the index when scanning disk.
With concurrent + realtime indexing, new metrics sent to Graphite would be visible once it’s delivered on the storage nodes.
Atomic store everywhere.
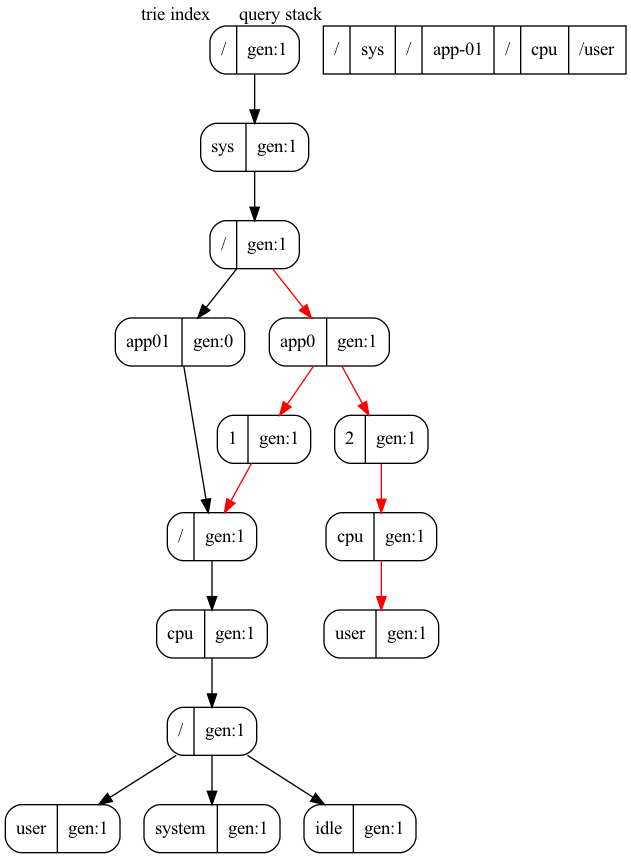
The way concurrent trie indexing works is through atomic updates. The trie index implemented in Go-Carbon is a compact prefix tree (radix tree). This means A few operations require atomic updates:
Apart from insert, pruning deleted metrics from the trie index tree is important. In our graphite installation, we periodically removed stale metrics to save spaces. The way Go-Carbon archive concurrent trie index updates are through generation marking.
Each time, when Go-Carbon started a new file system scan, a new generation mark is created, which is a simple integer, raised by 1.
When a metrics are being inserted, if it’s an existing metric, or has the trie node already exists, it generation id is set to the new value. If it’s a new trie node, it’s initialized with the new value.
After a full scan is completed, trie nodes previously built for metrics that are no longer exists on disk have an older generation value. Go-Carbon the walks over the whole trie tree and remove nodes with older generation value.
In contrast with insert, nodes might have to be merged while pruning if a parent node has only one child node. This is to make sure that the trie tree stays compact and remains similar to a trie index built by inserting all the metrics from scratch.
How does query cope with a concurrently updated trie tree? By using a stack/snapshot of currently visiting nodes.
While the writer is updating the index, a query might also be running against it. This means that different queries or even the same query might be traversing a different trie tree, but this is acceptable. The atomic updates guarantee that the query is either reading a short-lived snapshot of the old tree or getting the latest result.
After supporting concurrent update, realtime indexing in Go-Carbon becomes relatively trivial. All Go-Carbon needs is to have a new channel receving new metric names and perform a concurrent insert.
As always, testing if the concurrent indexing solution is working is as tricky as making it work.
Other than unit test, the most important verification process that I came out is continuously performing inserts and deletions by randomizing the metric names that I exported from production. Because the non-concurrent trie indexing was already proven to be working. So what I want to ensure in this process is that concurrent trie indexing works exactly the same as the non-concurrent one.
This process helped me identified a few critical bugs and make sure that the concurrent insert and prune process works as designed.
Memory usage was indeed lowered, but it’s mostly VSS, RSS improvement is less significant.
The implementation was actually completed last year. it’s only deployed to production few months ago and it appears to be working.
Now, a new metric being sent to Graphite will be visible around 1 minutes.
A good solution is always completed by a bug. After rolling out the concurrent trie. An interesting and nasty bug was reported and it took me more than 5 days to resolve it properly:
trie: fix empty directory related indexing and query bugs
There are two bugs fixed in this commit:
Empty directories not properly renewed during indexing (and could be trimmed at every two file list scans). During insert, trie.insert failed to bump up trie nodes properly if it’s inserting directory. This means that if the directory being inserted is empty and already exists in the trie tree, when concurrent index is enabled, the directory nodes might be pruned and then re-inserted in the next file list scan. And then on and on. This issue it self is not a serious concern if bug #2 below doesn’t exist.
Query logics do not handle well for empty directories. The symptoms are that if the trie index tree contains empty directories, and if a query happens to matching it, it would causes the query state stack (matchers) jump to the wrong index, and lead to incorrect matches of the metrics.
Context:
On our Graphite production, for cleanup purpose, we have daily cron jobs removing stale graphite metric files and empty directories in the whisper tree. The cronjob that removes files is run at 5AM and empty directory removal at 7AM. This means the above bugs have a time window of 1-2 hours being triggered. And because empty directories are not handled properly due to bug #1, the issue is triggered every 2 file list scans. Essentially, if the query matched an empty directory node and there are other metrics listed after the empty directory path, trie query can’t return proper result. In our case, it’s returning missing results, in theory, it could also return incorrect results.
In theory, these fixes are not needed because we stop indexing empty directory nodes in commit 67446d3. But it’s nice to figure out the root cause and resolve the issue properly!
Took me almost a week to figure it out! But I’m happy. Tears in rain.
Discuss on twitter:
Discuss on Twitter